
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 건대입구역
- Python
- 중식
- Podman
- 소모임
- 10km
- 한강
- Run The Bridge
- 러닝
- Kubernetes
- 대전
- 달리기
- 오답노트
- 뚝섬유원지
- 유산소
- 맛집
- 하체
- docker
- DSEC
- GitHub
- Shell
- Linux
- 성수대교
- Grafana
- zabbix
- 자전거
- 대구
- 2021
- 힐링
- 정보처리기사
- Today
- Total
Run The Bridge
k8s 7일차 본문
0. pod의 자원 사용량 제한
- 쿠버네티스에서는 클러스터를 구성하는 여러 대의 서버의 자원을 하나의 풀로 사용할 수 있다
- 자원이 부족하면 노드를 추가함으로써 수평적 확장이 가능하다
- 내부 자원 활용률을 올리는 것도 중요하므로 자원을 컨테이너에 할당하기 위한 여러 기능이 제공된다
서버를 클러스터에 추가해 리소스 풀의 크기를 늘리는 것을 Scale-Out
기존 서버에 CPU나 메모리 등을 추가로 꽂아 스펙을 높이는 것을 Scale-Up
기본적으로 k8s에서 CPU나 메모리 사용량을 명시하지않으면, 자원 할당량에 제한이 없어 무제한 사용이 가능


둘 다 500MB를 할당했지만, 한 쪽은 100MB도 쓰지못했고 한 쪽은 500MB 가깝게 사용중이다.
그래서 각 A, B 컨테이너에 750MB를 할당하고 사용량이 오버되면 오버커밋되게 설정한다.
하지만 이러한 방식은 메모리 사용률이 낮은 컨테이너에도 불필요하게 많은 메모리를 할당할 수도 있습니다.

request를 통해 컨테이너의 최소 자원 할당량을 보장해 줄 수 있다.

본문에 나와있듯이 Request를 사용하면, 자원 최대량보다 많이 설정할 수 없다.
limits - 컨테이너가 사용할 최대 자원 사용량
# vi resource-limit-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: resource-limit-pod
labels:
name: resource-limit-pod
spec:
containers:
- name: nginx
image: nginx:latest
resources:
limits:
memory: "256Mi" # 256MB
cpu: "1000m" # 1코어kubeclt apply -f resource-limit-pod.yaml # pod 실행k describe pod resource-limit-pod # QoS 확인방법
Requests - 컨테이너가 최소한으로 보장받아야 하는 자원의 양
# vi resource-limit-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: resource-limit-pod
labels:
name: resource-limit-pod
spec:
containers:
- name: nginx
image: nginx:latest
resources:
limits:
memory: "256Mi"
cpu: "1000m"
requests:
memory: "128Mi"
cpu: "500m"
최소한 128Mi의 메모리 사용은 보장되지만, 유후 메모리 자원이 있다면 최대 256Mi까지 사용할 수 있다
QoS 클래스와 메모리 자원 사용량 제한 원리
- CPU 자원에 경합이 발생하면 일시적으로 컨테이너 내부 프로세스에 CPU throttle이 걸릴 뿐, 컨테이너 자체에는 큰 문제가 발생하지 않는다(CPU는 compressible)
- 하지만 메모리 사용량에 경합이 발생하면 가용 메모리를 확보하기 위해 '우선순위가 낮은 포드 또는 프로세스를 강제로 종료한다. 강제로 종료된 포드는 다른 노드로 옮겨가는데 이를 퇴거(eviction)라고 표현
- 우선순위가 낮은 포드를 선택할 기준이 필요하고 3가지 종류의 QoS(Quality of Service) 클래스로 명시한다
kubectl describe nodes | grep -A9 Conditions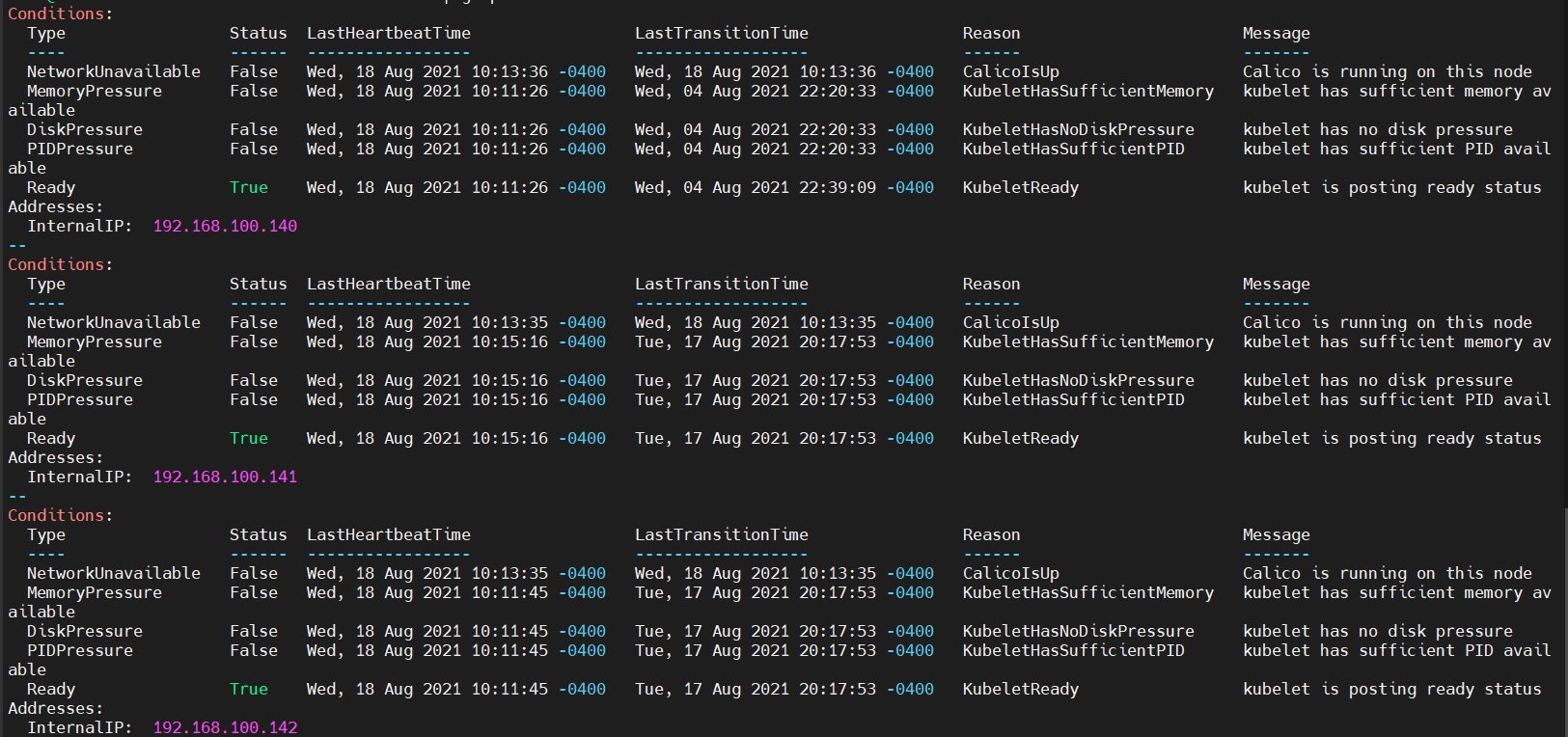
평소에 메모리가 부족하지 않을 때는 MemoryPressure의 값이 False로 설정되어 있습니다.
만약 node의 가용 메모리가 부족해지면 MemoryPressure 상태의 값이 True로 바뀝니다.
OOM(Out Of Memory) Killer 및 OOM Score
- OOM Killer는 리눅스의 기본 기능
- 모든 프로세스에 자동으로 OOM 점수가 매겨진다
- 종료되지 말아야 하는 핵심 프로세스는 OOM 점수가 매우 낮다
- 프로세스가 메모리를 얼마나 더 많이 사용하고 있는지에 따라 최종 OOM 점수가 갱신

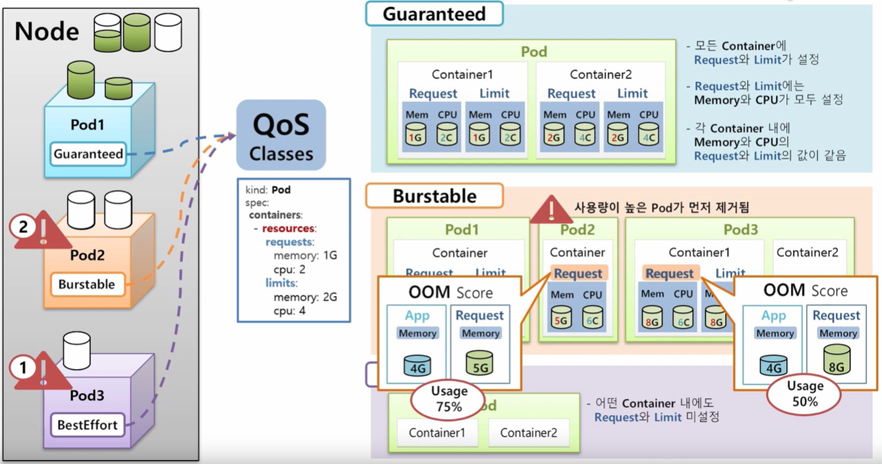
- 우선순위가 낮은 포드를 선택할 기준, QoS 클래스
- 쿠버네티스가 포드의 Limits와 Requests 설정값에 따라서 자동으로 설정한다
- Guaranteed - (Limits = Requests)로 설정된 포드
- Burstable - (Limits > Reuqests)로 설정된 포드
- BestEffort - (Limits, Requests)가 설정되지 않은 포드
ResourceQuota
- 네임스페이스에서 할당할 수 있는 자원(CPU, 메모리, PVC, 컨테이너 내부 임시 스토리지)의 총합을 제한
- 네임스페이스에서 생성할 수 있는 리소스(서비스, 디플로이먼트 등)의 개수를 제한
LimitRange
- 포드의 컨테이너에 CPU나 메모리 할당량이 설정돼 있지 않은 경우, 컨테이너에 자동으로 기본 Requests 또는 Limits 값을 설정
- 포드 또는 컨테이너의 CPU, 메모리, PVC 스토리지 크기의 최솟값/최댓값을 설정
# vi resource-quota
apiVersion: v1
kind: ResourceQuota
metadata:
name: resource-quota-example
namespace: default
spec:
hard:
requests.cpu: "1000m"
requests.memory: "500Mi"
limits.cpu: "1500m"
limits.memory: "1000Mi"
kubectl run memory-over-pod --image=nginx --requests='cpu=200m,memory=300Mi' --limits='cpu=200m,memory=3000Mi'
메모리 사용량은 1000Mi로 잡았지만, 3000Mi를 요청하면 오류가 난다.
# vi deployment-over-memory.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-over-memory
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "3000Mi"
cpu: "1000m"
requests:
memory: "128Mi"
cpu: "500m"kubectl apply -f deployment-over-memory.yamlkubectl get deploy # pod 명령으로는 볼 수 없다.
'포드를 생성하는 주체는 deployment가 아니라 replicaset' 이라는 점
deployment는 pod를 생성하기 위한 replicaset의 metadata를 선언적으로 가지고 있을 뿐, deployment resource가 직접 pod를 생성하지는 않는다. 따라서 포드 생성 거부에 대한 error_log는 replicaset에 남아 있을 것
kubectl get replicaset
kubectl describe rs [이름]
ResourceQuota로 제한할 수 있는 자원의 종류는 다양하다
- CPU, Memory
- Deployment, Pod, Service, Secret 등의 리소스의 개수
- NodePort 타입의 서비스 개수, LoadBalancer 타입의 서비스 개수
- QoS 클래스 중에서 BestEffort 클래스에 속하는 포드의 개수
LimitRange는 특정 네임스페이스에서 할당되는 자원의 범위 또는 기본값을 지정
- 포드의 컨테이너에 CPU나 메모리 할당량이 설정되어 있지 않은 경우
→ 컨테이너에 자동으로 기본 Requests, Limits 값을 설정 - 포드 또는 컨테이너의 CPU, 메모리, PVC 스토리지의 크기의 최솟값/최댓값 설정
# vi limitrange-example.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default:
memory: 256Mi
cpu: 200m
defaultRequest:
memory: 128Mi
cpu: 100m
max:
memory: 1Gi
cpu: 1000m
min:
memory: 16Mi
cpu: 50m
type: Containerk apply -f limitrange-example.yaml
k apply -f nginx-besteffort-pod # ns가 default인 pod 실행
ResourceQuota, LimitRange의 원리 : Admission Controller
Admission Controller
- 사용자의 API 요청이 적절한지 검증하고, 필요에 따라 API 요청을 변형하는 단계

- 사용자가 kubectl apply -f pod.yaml 명령어로 API 서버에 요청 전송한다
- x509 인증서, 서비스 어카운트 등을 통해 인증 단계를 거친다
- 롤, 클러스터롤 등을 통해 인가 단계를 거친다
- 어드미션 컨트롤러인 ResourceQuota는 해당 포드의 자원 할당 요청이 적절한지 검증(validation)한다. 만약 해당 포드로 인해 ResourceQuota에 설정된 네임스페이스의 최대 자원 할당량을 초과한다면 해당 API 요청은 거절된다
- 해당 API 요청에 포함된 포드 데이터의 자원 할당이 설정되지 않은 경우, 어드미션 컨트롤러인 LimitRange는 포드 데이터에 CPU 및 메모리 할당의 기본값을 추가함으로써 원래의 포드 생성 API의 데이터를 변경한다
쿠버네티스 스케줄링
- 쿠버네티스의 스케줄링이란 컨테이너나 가상 머신과 같은 인스턴스를 생성할 때, 그 인스턴스를 '어느 서버에 생성할 것인지 결정'하는 일을 의미
- 스케줄링이 중요한 이유
- 컨테이너가 특정 노드에 할당된 하드웨어 환경을 이용해야할 경우, 특정 노드를 선택하여 컨테이너를 실행해야 한다.
예를 들어, SSD가 장착된 노드를 사용해야 한다거나, GPU가 장착된 노드를 사용해야 할 때,
또는 컨테이너를 모든 노드에 고르게 배포해 무중단 서비스를 해야할 때
- 컨테이너가 특정 노드에 할당된 하드웨어 환경을 이용해야할 경우, 특정 노드를 선택하여 컨테이너를 실행해야 한다.

쿠버네티스에서 스케줄링에 관여하는 컴포터는 'kube-scheduler'와 'etcd' 가 있습니다.
kube-scheduler는 쿠버네티스 스케줄러에 해당
etcd는 쿠버네티스 클러스터의 전반적인 상태 데이터를 저장하는 일종의 DB 역할을 담당
쿠버네티스에서 제공하는 여러 가지 노드 스케줄링 방법
- nodeName과 nodeSelector를 이용하는 방법
- Node Affinity를 이용하는 방법
- Pod Affinity를 이용하는 방법
- Pod Anti-affinity를 이용하는 방법
- Taints와 Tolerations를 이용하는 방법
- Cordon, Drain, PodDistributionBudget를 이용하는 방법
- 그 외 커스텀 스케줄러를 구현하여 이용하는 방법
(실습1) nodeName을 이용하는 방법

# vi nodename-nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
nodeName: kube-master1
containers:
- name: nginx
image: nginx:latestkubectl apply -f nodename-nginx.yaml
(실습2) nodeSelector를 이용하는 방법

kubectl label node kube-worker1 mylabel/disk=ssd # worker1의 label를 추가한다.
kubectl label node kube-worker2 mylabel/disk=hdd # worker2의 label를 추가한다.root@kube-master1 ~/practice_11 # k get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
kube-master1 Ready master 13d v1.18.6 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kube-master1,kubernetes.io/os=linux,node-role.kubernetes.io/master=
kube-worker1 Ready <none> 13d v1.18.6 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kube-worker1,kubernetes.io/os=linux,mylabel/disk=ssd
kube-worker2 Ready <none> 13d v1.18.6 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kube-worker2,kubernetes.io/os=linux,mylabel/disk=hdd# vi nodeSelector-nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-nodeselector
spec:
nodeSelector:
mylabel/disk: hdd
containers:
- name: nginx
image: nginx:latestk apply -f nodeSelector.yaml
Taints와 Tolerations를 이용하는 방법
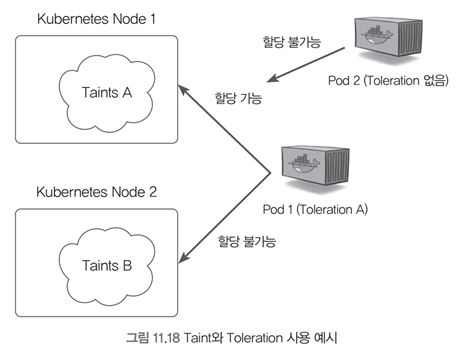
- Taints(얼룩) - 특정 노드에 얼룩을 지정하여 노드에 포드가 할당되는 것을 막는다
- Tolerations(용인) - 특정 포드에 설정하여 Taints가 설정된 노드에도 포드를 할당할 수 있다
→ 노드에 얼룩이 졌지만, 이를 용인할 수 있는 포드는 해당 노드에 할당될 수 있다는 개념
kubectl taint node kube-master1 alicek106/my-taint=dirty:NoSchedule # 생성
kubectl taint node kube-master1 alicek106/my-taint=dirty:NoSchedule- # 삭제
# vi toleration-test.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-toleration-test
spec:
tolerations:
- key: alicek106/my-taint
value: dirty
operator: Equal
effect: NoSchedule
containers:
- name: nginx
image: nginx:latestkubectl apply -f toleration-test.yaml # 실행
이렇게하면 worker에만 올라오는데 deployment로 설정해서 replica 3 정도 주면 master에도 올라오는 것을 볼 수 있다.
1. HPA를 활용한 오토스케일링
HPA - Horizontal Pod Autoscaler
k8s는 리소스 사용량에 따라 deployment나 replicaset의 pod 개수를 자동으로 조절하는 기능 제공

호출방법: kubectl get hpa
늘려야하는 조건이 필요하다. 기본적으로 CPU와 Memory 사용량이다.
(실습) metrics-server 설치
HPA를 사용하기 위해서는 리소스 메트릭 수집 도구를 설치해야 한다
기본적인 메트릭 수집 도구로는 metrics-server가 있다
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
kubectl edit deploy -n kube-system metrics-server - --authorization-always-allow-paths=/livez,/readyz
- --kubelet-insecure-tls
위의 두 줄을 추가해준다.


k top node # node별로 리소스 사용량을 볼 수 있다.
k top pod # pod마다 리소스 사용량 표시, ns 명시하지 않으면 default로 설정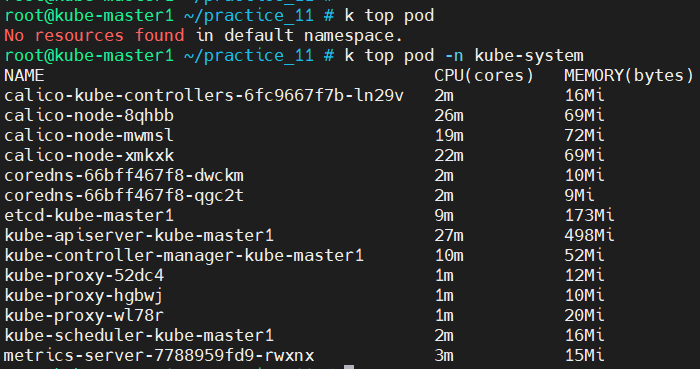
(실습) - HPA
# vi deployment-simple-hpa.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-simple-hpa
spec:
replicas: 3
selector:
matchLabels:
app: hpa-example
template:
metadata:
labels:
app: hpa-example
spec:
containers:
- name: hpa-example
image: gcr.io/google_containers/hpa-example
ports:
- name: http-port
containerPort: 80
resources:
requests:
cpu: 200mHPA를 설정할 떄는 자원에 관한 설정을 해주어야 한다.
# vi svc-simple-hpa.yaml
apiVersion: v1
kind: Service
metadata:
name: svc-simple-hpa
spec:
ports:
- name: web-port
port: 80
targetPort: 80
selector:
app: hpa-example
type: NodePort같이 사용할 Service도 올려준다.
HPA를 올려준다.
# vi simple-hpa.yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: simple-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: deployment-simple-hpa
targetCPUUtilizationPercentage: 50
maxReplicas: 5
minReplicas: 1
해당 image가 많은 리소스를 사용하도록 설정되어있기 때문에 우리는 service에 curl를 여러번 날려주면 된다.
kubectl run -i --tty --rm debug --image=alpine -- sh
/ #: apk add apache2-utils
/ #: for I in $(seq 1 5); do ab -c 5 -n 100000 http://simple-deployment-svc/; done;
'Cloud > k8s' 카테고리의 다른 글
| kubernetes install guide(v1.18.6) (0) | 2021.12.12 |
|---|---|
| k8s 8일차 (0) | 2021.08.19 |
| k8s 6일차 (0) | 2021.08.17 |
| docker-registry를 이용해 toyproject k8s에 deployment로 올리기 (0) | 2021.08.16 |
| k8s 5일차 (0) | 2021.08.13 |



